רגע! לפני שהולכים... 👋
אל תפספסו! מסלולי לימוד נפתחים בקרוב - מקומות מוגבלים
| מסלול Machine Learning | 31/03 |
| מסלול Computer Vision | 31/03 |
| מסלול RT Embedded Linux | 15/04 |
| מסלול Cyber | 15/04 |
| מסלול Full Stack | 03/05 |
✓ ייעוץ אישי ללא התחייבות | תשובה תוך 24 שעות
רשתות נוירונים: ארכיטקטורה ומודל מובנה לטיפול בנתונים שונים
עודכן לאחרונה: 22 אוקטובר, 2025

ההבדלים בין רשתות נוירונים
רשתות נוירונים הן הליבה של עולם למידת המכונה, והן מחקות את פעולת המוח האנושי כדי ללמוד מנתונים ולבצע משימות מורכבות. קיימים סוגים שונים של רשתות, שכל אחת מהן מותאמת לסוג נתונים ולבעיות שונות. נסקור כאן את ההבדלים העיקריים בין רשתות נוירונים בסיסיות, רשתות קונבולוציה (CNN), ורשתות רקורנטיות (RNN) ו-LSTM.
רשתות נוירונים בסיסיות (Neural Networks / Multilayer Perceptrons)
מהי הרשת ואיך היא עובדת? רשת נוירונים בסיסית, הידועה גם כ-Multilayer Perceptron (MLP), מורכבת משכבות של נוירונים (יחידות חישוב). כל נוירון בשכבה אחת מחובר לכל הנוירונים בשכבה הבאה, ומקבל את הפלטים שלהם כקלט. התהליך מתחיל בשכבת הקלט, עובר דרך אחת או יותר שכבות נסתרות, ומסתיים בשכבת הפלט. כל קשר בין נוירונים מקבל "משקל", והרשת לומדת על ידי שינוי משקלים אלה כדי למזער את שגיאת החיזוי.
יתרונות וחסרונות:
- יתרונות: פשוטות יחסית להבנה וליישום, יעילות למגוון רחב של משימות כמו סיווג ורגרסיה של נתונים טבלאיים.
- חסרונות: לא יעילות במיוחד לנתונים עם מבנה מובנה כמו תמונות או טקסט, מכיוון שהן מתעלמות מהקשר המרחבי או הכרונולוגי בין הנתונים.
מתי להשתמש בה? מתאימה בעיקר לבעיות סיווג ורגרסיה בנתונים שאינם מובנים (Tabular Data), כמו זיהוי הונאות על בסיס נתוני רכישות, או חיזוי מחירי בתים לפי מאפיינים שונים.
יעילות: יעילותן תלויה בגודל הנתונים וביכולת התאמה למבנה שלהם. הן פחות יעילות עבור משימות שדורשות הבנת הקשרים המרחביים או הרצפיים.
Frameworks: TensorFlow, PyTorch, Keras, Scikit-learn (במידה מצומצמת).
רשתות קונבולוציה (CNN – Convolutional Neural Networks)
מהי הרשת ואיך היא עובדת? רשתות CNN מותאמות במיוחד לעיבוד נתונים מרחביים כמו תמונות. הן משתמשות בשכבות קונבולוציה (Convolutional layers) שבהן מסננים (Filters) קטנים "מחליקים" על גבי התמונה. כל מסנן מזהה תבניות מסוימות כמו קצוות, טקסטורות או צורות. הפלטים של שכבת הקונבולוציה עוברים Pooling כדי להפחית את ממדי הנתונים, ולאחר מכן מועברים לשכבות נוירונים רגילות לסיווג סופי.
יתרונות וחסרונות:
- יתרונות: יעילות באופן יוצא דופן בזיהוי תבניות מרחביות. הן רגישות למיקום, גודל וסיבוב של עצמים.
- חסרונות: פחות מתאימות לנתונים שאינם תמונות, כמו נתוני טקסט או נתונים טבלאיים.
מתי להשתמש בה? השימוש העיקרי הוא בתחום ראייה ממוחשבת, לדוגמה: זיהוי פנים, סיווג תמונות (חתול מול כלב), זיהוי אובייקטים בכביש עבור מכוניות אוטונומיות, ופענוח תמונות רפואיות (אבחון רנטגן, MRI).
יעילות: נחשבות לסטנדרט דה פקטו בתחום ראייה ממוחשבת, עם ביצועים שהגיעו לרמות על-אנושיות במשימות רבות.
Frameworks: TensorFlow, PyTorch, Keras.
רשתות רקורנטיות (RNN – Recurrent Neural Networks) ו-LSTM
מהי הרשת ואיך היא עובדת? רשתות RNN נועדו לעיבוד נתונים רצפיים כמו טקסט, דיבור וסדרות זמן. הן נבדלות מרשתות אחרות בכך שהן מכילות לולאה פנימית שמאפשרת להן לשמור על "זיכרון" של הנתונים הקודמים ברצף. כל נוירון מקבל לא רק את הקלט הנוכחי, אלא גם את הפלט מהצעד הקודם. LSTM (Long Short-Term Memory) הן גרסה משופרת של RNN שמתמודדות עם בעיית ה"זיכרון הנעלם" (Vanishing Gradient Problem), בכך שהן יכולות לשמור על מידע לטווח ארוך או קצר באמצעות "שערים" (Gates) מיוחדים ששולטים בזרימת המידע.
יתרונות וחסרונות:
- יתרונות: יכולות ללמוד ולהבין קשרים בין נתונים שמופיעים ברצף, לדוגמה הקשר בין מילים שונות במשפט. הן טובות במיוחד לבעיות חיזוי על בסיס נתוני עבר.
- חסרונות: רשתות RNN בסיסיות סובלות מבעיות של זכירה לטווח ארוך. תהליך האימון של שתיהן איטי ומורכב.
מתי להשתמש בה? מתאימות למשימות עיבוד שפה טבעית (NLP) כמו תרגום מכונה (מפליטים טקסט בשפה אחת לטקסט בשפה אחרת), יצירת טקסט, ניתוח סנטימנט, זיהוי דיבור וחיזוי סדרות זמן (כמו מחירי מניות).
יעילות: LSTM נחשבות ליעילות מאוד עבור משימות שבהן נדרשת זיכרון לטווח ארוך, והן שימשו בבסיס של מודלים רבים לפני המעבר למודל טרנספורמרים.
Frameworks: TensorFlow, PyTorch, Keras.
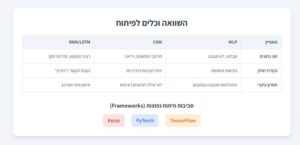
השוואה בין רשתות
קטגוריה | רשתות נוירונים (MLP) | רשתות קונבולוציה (CNN) | רשתות רקורנטיות (RNN / LSTM) |
סוג נתונים | טבלאיים / לא מובנים | תמונות / נתונים מרחביים | טקסט / סאונד / סדרות זמן (נתונים רצפיים) |
יכולות | סיווג ורגרסיה בסיסיים | זיהוי תבניות וסיווג תמונות | הבנת רצפים וזיכרון לטווח ארוך (LSTM) |
יתרונות | פשוטה, גמישה לנתונים שונים | מצטיינת בראייה ממוחשבת | מצטיינת בעיבוד שפה טבעית וסדרות זמן |
חסרונות | לא מותאמת לנתונים מורכבים | לא מותאמת לנתונים רצפיים | אימון איטי, קושי בזיכרון לטווח ארוך (ב-RNN בסיסי) |
שימוש נפוץ | זיהוי הונאה, חיזוי מחירים | זיהוי פנים, סיווג תמונות | תרגום מכונה, ניתוח סנטימנט |
Frameworks | Keras, PyTorch, TensorFlow | Keras, PyTorch, TensorFlow | Keras, PyTorch, TensorFlow |
בטבלה הזו סקרתי ממש על קצה המזלג רשתות נוירונים מרכזיות, תוך התמקדות בהבדלים המהותיים ביניהן, יתרונותיהן, חסרונותיהן ויישומן במגוון משימות למידת מכונה. הדוח מפרט את העקרונות הבסיסיים של רשתות נוירונים מלאכותיות (ANNs), ומסביר כיצד הן מהוות את הבסיס לארכיטקטורות מתקדמות יותר כמו רשתות קונבולוציה (CNNs) ורשתות חוזרות (RNNs), שכל אחת מהן נועדה לטפל בסוג נתונים ספציפי באופן אופטימלי.
יסודות רשתות נתונים ANNs
הגדרה ומושגי יסוד
רשתות נוירונים מלאכותיות (ANNs), המכונות גם רשתות Feedforward או Multilayer Perceptrons (MLPs), מהוות את אבן היסוד של תחום הלמידה העמוקה. ארכיטקטורות אלו שואבות השראה ישירה מהמבנה והתפקוד של המוח האנושי, במטרה לחקות את יכולת הלמידה שלו באמצעות רשתות של נוירונים מחוברים.
כל ANN מורכבת משכבות של "נוירונים" מלאכותיים המחוברים זה לזה. לרשתות מסוג זה יש שלוש שכבות עיקריות:
- שכבת קלט (Input Layer): מקבלת את הנתונים הגולמיים, כאשר מספר הנוירונים בשכבה זו תואם את מספר המאפיינים (Features) בנתוני הקלט.
- שכבות נסתרות (Hidden Layers): שכבות הביניים שבהן מתרחש עיבוד הנתונים. ברשתות עמוקות (Deep Neural Networks - DNNs), עשויות להיות שכבות נסתרות מרובות. תפקידן הוא לחלץ תכונות וייצוגים מופשטים יותר של הנתונים.
- שכבת פלט (Output Layer): מייצרת את התוצאה הסופית או התחזית של המודל.
הקלט והפלט של כל נוירון הם ערכים מספריים, והעיבוד מתבצע על בסיס קבוצה של משקלים (Weights) והטיות (Biases). המשקלים מייצגים את עוצמת החיבור בין נוירונים, ואילו ההטיות מאפשרות לכייל את פעולת הנוירון. זרימת המידע מתבצעת בכיוון אחד בלבד, משכבת הקלט דרך השכבות הנסתרות אל שכבת הפלט, ומכאן הכינוי 'feedforward'.
מנגנון הלמידה: התפשטות קדימה ואחורה
האימון של רשת נוירונים הוא תהליך של מציאת המשקלים וההטיות האופטימליים שיניבו תחזיות מדויקות. תהליך זה מתבסס על שני עקרונות יסודיים:
- התפשטות קדימה (Forward Propagation): זהו תהליך ההעברה של נתוני הקלט דרך הרשת כדי לקבל פלט. כל נוירון בשכבה מקבל קלט מכל הנוירונים בשכבה הקודמת, מכפיל אותם במשקלים המתאימים, מוסיף את ההטיה, ומפעיל על התוצאה
- פונקציית הפעלה (Activation Function). פונקציות הפעלה, כמו ReLU או Sigmoid, הן קריטיות מכיוון שהן מוסיפות אי-לינאריות לרשת. ללא אי-לינאריות, הרשת כולה הייתה שקולה לפעולה ליניארית אחת בלבד, ולא הייתה יכולה ללמוד קשרים מורכבים בנתונים.
- התפשטות אחורה (Backpropagation): לאחר שהרשת הפיקה פלט, הוא מושווה לפלט האמיתי, והשגיאה (Error) מחושבת. מנגנון ההתפשטות אחורה משתמש בשגיאה זו כדי לעדכן באופן איטרטיבי את המשקלים ואת ההטיות של הרשת, במטרה לשפר את דיוק התחזיות. עדכון המשקלים מתבצע באמצעות אלגוריתם אופטימיזציה, כגון ירידה בדרגה סטוקסטית (SGD), שמטרתו למזער את פונקציית ההפסד (Loss Function) המודדת את הפער בין הפלט החזוי לתוויות האמת.
יתרונות וחסרונות מרכזיים של ANNs
רשתות ANNs הן גמישות ומתאימות למגוון רחב של בעיות, במיוחד כאלה המבוססות על נתונים מובנים (Structured Data), כגון נתוני אשראי או חיזוי לקוחות. הן מסוגלות לזהות דפוסים לא לינאריים מורכבים.
עם זאת, רשתות ANNs מציגות חוסר יעילות מובהק בטיפול בסוגי נתונים בעלי טופולוגיה מובנית, כגון תמונות או רצפים. הסיבה לכך נעוצה בארכיטקטורת הקישוריות המלאה שלהן. עבור קלט בעל ממדים גבוהים, כמו תמונה בגודל 100x100 פיקסלים, כל נוירון בשכבה הנסתרת הראשונה יצטרך חיבור לכל 10,000 הפיקסלים של תמונת הקלט. כתוצאה מכך, מספר הפרמטרים (משקלים) הופך להיות עצום, מה שמגדיל דרמטית את העלות החישובית, דורש כמויות גדולות מאוד של נתוני אימון, ומעלה את הסיכון להתאמת יתר (Overfitting) של המודל לנתוני האימון. כמו כן, רשתות אלו אינן לוקחות בחשבון את הקשרים המרחביים או הרצפיים הקיימים בנתונים, מאחר שהן מעבדות אותם כוקטור חד-ממדי "שטוח". ארכיטקטורות ה-CNN וה-RNN נוצרו בדיוק כדי להתמודד עם מגבלות אלו.
רשתות CNN עיבוד תמונה ונתונים מרחביים
רשתות קונבולוציה (CNN):
מהי CNN? ארכיטקטורה ועקרונות ייחודיים
רשת קונבולוציה (CNN) היא סוג של רשת נוירונים שתוכננה במיוחד כדי לטפל בנתונים בעלי מבנה מרחבי (Spatial Structure), כגון תמונות וסרטוני וידאו. שם נוסף מתאים לה הוא "רשת עצבית מלאכותית בלתי תלויה במרחב" (Space Invariant Artificial Neural Network - SIANN).
הארכיטקטורה של CNN מבוססת על שלושה סוגי שכבות מרכזיות:
- שכבת קונבולוציה (Convolutional Layer): שכבה זו היא אבן הבניין העיקרית של ה-CNN. היא פועלת על ידי העברת
- מסננת (Filter) או ליבה (Kernel) קטנה על פני תמונת הקלט, תוך ביצוע פעולה של כפל מטריצות בכל נקודה. הפלט של פעולה זו מכונה מפת תכונות (Feature Map). היפרפרמטרים חשובים המשפיעים על תהליך זה הם גודל הליבה, גודל הפסיעה (Stride), המגדיר את גודל הקפיצה של המסננת, וריפוד (Padding), המוסיף פיקסלים מסביב לתמונה כדי לשמר את גודלה.
- שכבת אגרגציה (Pooling Layer): תפקידה העיקרי הוא להקטין את הממדים של מפת התכונות, מה שמוריד את העומס החישובי ומסייע במניעת התאמת יתר. לדוגמה, שכבת Max Pooling לוקחת את הערך המקסימלי מכל "חלון" קטן במפת התכונות.
- שכבה מחוברת במלואה (Fully Connected Layer): השכבה האחרונה ברשת, המקבלת את מפות התכונות המופשטות ומסווגת אותן לקטגוריה הסופית.
יתרונות, חסרונות ויעילות
היתרון העיקרי של CNNs, שהופך אותן ליעילות כל כך בעיבוד נתונים מרחביים, הוא השילוב של מספר עקרונות הנדסיים מובנים:
- שיתוף פרמטרים (Parameter Sharing): בניגוד ל-ANNs, שבהן לכל חיבור יש משקל ייחודי, ב-CNNs אותה מסננת משמשת לחלקים שונים של הקלט. מנגנון זה מפחית דרמטית את מספר הפרמטרים הנלמדים , מה שמשפר את היעילות החישובית ומפחית את הסיכון להתאמת יתר. לדוגמה, שכבת קונבולוציה עם ליבה בגודל 5×5 יוצרת 25 משתנים למידים בלבד, בניגוד ל-10,000 משקולות שדורש נוירון בודד ב-ANN עבור תמונה בגודל 100×100.
- חילוץ תכונות אוטומטי (Automatic Feature Extraction): רשתות CNN לומדות לזהות תכונות היררכיות באופן אוטומטי, ללא צורך בהנדסת תכונות ידנית. בשכבות המוקדמות הן מזהות מאפיינים פשוטים כמו קצוות ומרקמים, ובשכבות העמוקות יותר הן משלבות אותם כדי לזהות מאפיינים מורכבים יותר כמו עיניים, אוזניים, ופנים שלמות.
- אי-תלות במיקום (Spatial Invariance): בזכות תהליך הקונבולוציה, ה-CNN מסוגלת לזהות תכונה מסוימת ללא קשר למיקומה בתמונה.
ההצלחה הגדולה של רשתות CNN בתחום הראייה הממוחשבת אינה תוצר של יכולת למידה "טהורה" בלבד, אלא של תכנון ארכיטקטוני מוקדם המוטמע ברשת. רשתות נוירונים עמוקות רגילות מתקשות לעבד קלט בעל ממד גבוה מאוד כמו תמונות. הדרך שבה CNNs מצליחות ללמוד היא על ידי כך שהן מחקות את האופן שבו המוח האנושי מעבד מידע חזותי - לא על בסיס פיקסל בודד, אלא על בסיס קשרים מקומיים והיררכיות של הבנה. הארכיטקטורה הייחודית של CNN, עם שיתוף הפרמטרים והליבות הקטנות, היא למעשה ידע אנושי מובנה מראש אודות מבנה המרחב, המאפשר לרשת להתמודד עם משימות מורכבות ביעילות חסרת תקדים.
עם זאת, ל-CNNs יש גם חסרונות, והעיקרי שבהם הוא הדרישה לכמויות גדולות של נתוני אימון מתויגים כדי ללמוד ביעילות.
מתי להשתמש ב-CNN: יישומים נפוצים
CNNs חזקות במיוחד למשימות הכרוכות בזיהוי וניתוח של נתונים חזותיים. יישומים נפוצים כוללים:
- סיווג תמונה וזיהוי אובייקטים: זיהוי חפצים, פנים (למשל, זיהוי פנים בזמן אמת) או בעלי חיים בתמונות.
- ניתוח וידאו: עיבוד פריימים בסרטון לצורך זיהוי תנועה, מעקב אחר אובייקטים או יצירת תיאורים של תוכן וידאו.
- הדמיה רפואית: ניתוח צילומי רנטגן, סריקות CT או MRI לצורך אבחון מוקדם של מחלות, כגון זיהוי גידולים.
- מכוניות אוטונומיות: עיבוד נתוני חיישנים כדי לזהות הולכי רגל, תמרורים ומכשולים בדרכים.
רשתות חוזרות (RNN) ורשתות LSTM: עיבוד נתונים עוקבים
. מבוא ל-RNN: תפקיד הזיכרון והאתגרים
רשתות נוירונים חוזרות (Recurrent Neural Networks - RNNs) תוכננו במיוחד לטיפול בנתונים עוקבים (Sequential Data), כגון טקסט, אודיו או סדרות זמן. הייחודיות שלהן היא במבנה הלולאה, המאפשר להן להעביר מידע מצעד זמן אחד למשנהו. המידע הזה נשמר ב
מצב נסתר (Hidden State), המקנה לרשת סוג של "זיכרון" של אירועים קודמים ברצף.
עם זאת, רשתות RNN רגילות סובלות מבעיה מהותית הידועה כבעיית ה-Vanishing Gradient. בתהליך הלמידה על רצפים ארוכים, השיפועים (Gradients) המשמשים לעדכון המשקלים הולכים וקטנים ככל שהם מתפשטים אחורה, עד שהם כמעט נעלמים. כתוצאה מכך, ה-RNN מאבדת את היכולת לשמר וללמוד קשרים ארוכי טווח בנתונים. לדוגמה, במשימת חיזוי מילה במשפט, RNN רגילה עשויה להתקשות לחבר הקשר שהוצג בתחילת משפט ארוך לחיזוי של מילה בסופו.
3.2. מבנה ה-LSTM: פתרון לבעיית הזיכרון
כדי להתגבר על בעיית ה-Vanishing Gradient, הוצגה גרסה מתקדמת של RNN בשם Long Short-Term Memory (LSTM). רשתות LSTM הן סוג של RNNs, אך הן כוללות ארכיטקטורה פנימית מורכבת יותר, המאפשרת להן לזכור מידע למשך פרקי זמן ארוכים יותר.
המרכיב המרכזי של תא LSTM הוא מצב התא (Cell State), המכונה גם "מסוע". זהו קו אופקי העובר דרך כל התא, והוא נועד להעביר מידע לאורך הרצף עם מינימום שינוי. יכולת השמירה והשליפה של מידע ממצב התא מבוקרת בקפידה על ידי שלושה
שערים (Gates):
- שער השכחה (Forget Gate): מחליט איזה מידע ממצב התא הקודם יש לזרוק. הוא פועל באמצעות שכבת Sigmoid המפיקה ערכים בין 0 ל-1, כאשר 0 משמעותו "שכח לחלוטין" ו-1 משמעותו "שמור לחלוטין".
- שער הקלט (Input Gate): מחליט איזה מידע חדש מועיל וצריך להתווסף למצב התא.
- שער הפלט (Output Gate): מחליט איזה חלק ממצב התא יש להעביר למצב הנסתר הבא ולפלט הנוכחי.
בניגוד ל-RNN רגילה שבה מידע הולך לאיבוד באופן פסיבי לאורך הרצף, ב-LSTM, מנגנוני השערים מאפשרים "ניהול אקטיבי" של הזיכרון. הרשת יכולה להחליט באופן מודע איזה מידע קודם חשוב לשמר לאורך זמן (כמו נושא שיחה) ואיזה מידע יש להשליך (כמו מילות חיבור או מילות קישור חוזרות), וזוהי הסיבה לכך ש-LSTMs מצטיינות במשימות תלות ארוכות טווח.
3.3. השוואה ושימושים של RNN ו-LSTM
LSTM נחשבת לסוג מתקדם של RNN. הטבלה הבאה מסכמת את ההבדלים העיקריים ביניהן:
מאפיין | RNN (Recurrent Neural Network) | LSTM (Long Short-Term Memory) |
מבנה בסיסי | יחידה חוזרת פשוטה | תא זיכרון מורכב עם שערים |
יכולת זיכרון | טווח קצר; מתקשה לזכור מידע מצעדים קודמים | טווח ארוך; יכולה לשמר מידע למשך זמן רב |
בעיות גרדיאנטים | סובלת מבעיות vanishing/exploding gradients | נועדה למנוע את בעיית ה-vanishing gradient |
יעילות חישובית | פשוטה יותר, מהירה יותר לאימון במשימות קצרות | מורכבת יותר, דורשת יותר משאבים וזמן אימון |
מתי להשתמש | משימות עם תלות קצרת טווח, נתונים פשוטים | משימות מורכבות עם תלות ארוכת טווח |
LSTMs נחשבות כיום לבחירה המועדפת במרבית המשימות של נתונים עוקבים בזכות יכולתן לטפל באתגרים של RNN רגילות. יישומים נפוצים של LSTMs כוללים:
- עיבוד שפה טבעית (NLP): תרגום מכונה (למשל, Google Translate), ניתוח סנטימנטים ויצירת טקסט.
- זיהוי דיבור (Speech Recognition): ניתוח רצפים קוליים.
- חיזוי סדרות זמן: חיזוי מחירי מניות, רמות הצפה בנהרות ועוד.
השוואה מעמיקה בין הארכיטקטורות השונות
טבלה השוואתית מפורטת
הטבלה הבאה מסכמת את ההבדלים המרכזיים בין סוגי הרשתות השונות, ומציגה את היתרונות והחסרונות של כל ארכיטקטורה ביחס לסוגי נתונים ומשימות שונות.
מאפיין | ANNs (Multilayer Perceptrons) | CNNs (Convolutional Networks) | RNNs / LSTMs (Recurrent Networks) |
ארכיטקטורה בסיסית | שכבות מחוברות במלואן (Fully Connected) | שכבות קונבולוציה ואגרגציה | לולאה חוזרת המעבירה מצב נסתר |
סוגי נתונים מועדפים | נתונים מובנים כלליים (טבלאות) | נתונים מרחביים (תמונות, וידאו) | נתונים עוקבים (טקסט, סאונד, סדרות זמן) |
מנגנון ייחודי | התפשטות אחורה (Backpropagation) | שיתוף פרמטרים וחילוץ תכונות היררכי | זיכרון חוזר (מצב נסתר) ושערים ב-LSTM |
יכולת זיכרון | אין זיכרון של קלט קודם | אין זיכרון של קלט קודם | יכולת לזכור מידע קודם ברצף |
יתרונות מובהקים | גמישות, פשטות יחסית, יכולת למידת דפוסים לא לינאריים | יעילות פרמטרית, חילוץ תכונות אוטומטי, אי-תלות במיקום | מתאימות במיוחד לנתונים עוקבים, LSTMs פותרות את בעיית הזיכרון ארוך הטווח |
חסרונות מובהקים | לא יעילות עבור נתונים בעלי מבנה מרחבי/רצפי , מספר פרמטרים עצום | דורשות כמויות גדולות של נתונים מתויגים, מורכבות | RNN רגילות סובלות מ-vanishing gradient, איטיות יחסית |
יישומים נפוצים | סיווג נתונים, זיהוי הונאות, חיזוי לקוחות | זיהוי תמונה, סיווג אובייקטים, הדמיה רפואית | תרגום מכונה, יצירת טקסט, זיהוי דיבור |
קומבינציות היברידיות
הבחירה בארכיטקטורה ספציפית תלויה בסוג הנתונים ובבעיה, אך חשוב לציין שניתן לשלב בין ארכיטקטורות שונות ליצירת מודלים היברידיים ורבי עוצמה. לדוגמה, במשימות של ניתוח וידאו או תיאור תמונה, ניתן להשתמש ב-CNN כדי לחלץ תכונות מרחביות מכל פריים בנפרד, ולאחר מכן להזין את התכונות הללו לרשת RNN או LSTM, שתעבד את רצף הפריים כדי להבין את האירועים והתנועה לאורך זמן. דוגמה נוספת היא מודל המשלב CNN לזיהוי האובייקטים בתמונה ו-RNN ליצירת תיאור טקסטואלי של התמונה כולה.
Frameworks: כלים לבניית הרשתות
סקירה כללית של ספריות פיתוח מובילות
פיתוח רשתות נוירונים מתבצע באמצעות ספריות תוכנה ייעודיות, המכונות Frameworks. ספריות אלה מפשטות את תהליך הבנייה, האימון והפריסה של מודלים מורכבים. שתי הספריות המובילות והנפוצות ביותר בתחום כיום הן
TensorFlow ו-PyTorch.
השוואה בין TensorFlow ל-PyTorch
בעבר, TensorFlow ו-PyTorch נבדלו באופן מהותי בגישתן לגרפים חישוביים:
- TensorFlow: התבססה במקור על גרף חישובי סטטי, בו המשתמש היה צריך להגדיר את כל מבנה הרשת מראש לפני הפעלתה. גישה זו יעילה בייצור וביצועים, אך הקשתה על ניפוי באגים (Debugging) ועל גמישות בתהליך הפיתוח.
- PyTorch: התבלטה בזכות הגרף הדינמי, שאפשר לבנות את הרשת "על הדרך" תוך כדי ביצוע התוכנית. גמישות זו הפכה את PyTorch לאינטואיטיבית במיוחד עבור חוקרים ואפשרה יצירת פרוטוטיפים מהירה.
עם זאת, ההבדלים בין שתי הספריות היטשטשו באופן משמעותי עם השקת TensorFlow 2.0, שאימצה את תכונת ה-Eager Execution שאפשרה גרפים דינמיים. כיום, הבחירה בין השתיים היא לרוב עניין של העדפה אישית או סביבת העבודה:
- TensorFlow: נתמכת על ידי גוגל ומועדפת בתעשייה, במיוחד עבור פריסת מודלים בקנה מידה גדול והטמעה במוצרי קצה. האקוסיסטם שלה מותאם יותר לפתרונות מקצה לקצה.
- PyTorch: צברה תאוצה רבה בקהילה המדעית והאקדמית ומומלצת למחקר, ניסויים ופיתוח פרוטוטיפים מהירים.
Keras: הפשטה ונוחות שימוש
Keras היא ספריית תוכנה חשובה נוספת, אך היא אינה Framework עצמאי אלא API (Application Programming Interface) ברמה גבוהה. היא רצה על גבי Frameworks אחרים כמו TensorFlow ו-PyTorch, ומטרתה העיקרית היא לפשט את בניית רשתות הנוירונים. Keras מאפשרת למפתחים ליצור מודלים במהירות באמצעות קוד קומפקטי וקריא, והיא ידועה בסיכון נמוך יותר לטעויות ובדיוק גבוה יותר של המודלים שהיא בונה.
המלצות פרקטיות לבחירת Framework
הבחירה ב-Framework הנכון תלויה ביעדים של הפרויקט ובשלב הפיתוח.
Framework | קלות שימוש | גמישות (גרף חישובי) | שימוש נפוץ |
TensorFlow | סביר (אינטואיטיבי עם Eager Execution) | סטטי (היסטורית) / דינמי (בגרסאות מתקדמות) | פריסת מודלים לייצור בקנה מידה גדול |
PyTorch | גבוהה (אינטואיטיבית, קלה לניפוי באגים) | דינמי | מחקר אקדמי, פיתוח פרוטוטיפים |
Keras | גבוהה מאוד (קלה ללמידה ושימוש) | תלויה ב-backend (TensorFlow, PyTorch) | מתחילים, פיתוח מהיר, בניית מודלים מורכבים בקלות |
למפתחים מתחילים ולפרויקטים שמתמקדים בפיתוח מהיר, Keras היא בחירה מצוינת. עבור פרויקטים הדורשים גמישות ניסיונית ומחקר מתקדם, PyTorch מציעה יתרון מובהק. לעומת זאת, לפרויקטים שצריכים להתקדם בקלות לייצור בקנה מידה גדול, במיוחד בסביבה ארגונית, TensorFlow עדיין נחשבת בחירה מובילה.
סיכום והמלצות יישומיות
ההבדל המהותי בין רשתות נוירונים שונות נעוץ בארכיטקטורה הייחודית שלהן, שהונדסה במיוחד כדי להתמודד עם המאפיינים הספציפיים של סוגי נתונים שונים. הבסיס, ה-ANN, מתאים לנתונים מובנים כלליים, אך הקישוריות המלאה שלו הופכת אותו לבלתי יעיל עבור נתונים בעלי מבנה פנימי, כגון תמונות ורצפים.
כמענה למגבלות אלו, פותחו ארכיטקטורות ייעודיות שהוסיפו מנגנונים חדשים, המפחיתים את העומס החישובי ומייצגים את מבנה הנתונים בצורה יעילה:
- CNNs מצטיינות בטיפול בנתונים מרחביים, באמצעות מנגנונים כמו שיתוף פרמטרים וחילוץ תכונות היררכי. זהו הסטנדרט כיום בתחום הראייה הממוחשבת.
- RNNs וגרסתם המתקדמת LSTMs חיוניות לטיפול בנתונים עוקבים, בזכות יכולתן לזכור מידע קודם ברצף. במשימות הדורשות זיכרון לטווח ארוך, LSTMs עולות באופן ניכר על RNN רגילות בזכות מנגנוני השערים החכמים שלהן.
חשוב להבין שאין רשת אחת ש"טובה" יותר מהשנייה. הבחירה הנכונה תלויה באופן מוחלט בסוג הנתונים ובמטרה של הפרויקט. יתרה מכך, התחום ממשיך להתפתח כל העת, עם הופעתן של ארכיטקטורות חדשות כמו מודלי Transformer, שחוללו מהפכה בעיבוד שפה טבעית ומשמשות כיום גם בראייה ממוחשבת, מה שמאשר כי התכנון הארכיטקטוני הוא המפתח להצלחה ביישומי למידה עמוקה.