רגע! לפני שהולכים... 👋
אל תפספסו! מסלולי לימוד נפתחים בקרוב - מקומות מוגבלים
| מסלול Cyber | 30/07 |
| מסלול Machine Learning | 30/07 |
| מסלול Computer Vision | 30/07 |
| מסלול RT Embedded Linux | 02/08 |
✓ ייעוץ אישי ללא התחייבות | תשובה תוך 24 שעות
המדריך המלא מה זה ‑ DevOps: למה זה קריטי ואיך מתחילים?
עודכן לאחרונה: 13 מאי, 2026

- הסבר קצר מה זה Devops
- מה אנשי Devops באו לפתור
- תרבות (Culture)
- אוטומציה (Automation)
- המשכיות (Continuous Everything)
- מדידה (Measurement)
- שיתוף (Sharing)
- עקרונות נוספים חשובים
- אז למה צריך דבאופס?
- מחזור החיים של Devops
- הכלים הנפוצים לשימוש של אנשיי Devops
- מעבר לכלים: תרבות ה-DevOps
- ההצדקה והמדדים לאנשי דבאופס
- יום בחיי איש דבאופס
- טבלת שכר דבאופס
- איך ללמוד להיות איש Devops
- שאלות נפוצות FAQ
הסבר קצר מה זה Devops
מה זה DevOps (קיצור של Development ו‑Operations)
זה לא רק מקצוע, זו מתודולוגיה ותרבות עבודה המשלבת בין פיתוח תוכנה (Development) לתפעול מערכות (Operations), במטרה לייעל תהליכים, לקצר זמני פיתוח ופריסה (Deployment), ולהשיג אוטומציה, זריזות ויציבות מרבית בסביבת הפיתוח והייצור.
למה זה המקצוע הכי מרתק בעולם הטכנולוגיה
להכיר את קורס DevOps של RT-ED
דמיינו רגע שאתם קוסמים בעידן דיגיטלי — לא עם שרביט, אלא עם שורת קוד אחת שמשנה את המציאות. זה בדיוק מה שעושה איש DevOps. בעוד רוב אנשי הטכנולוגיה מתמקדים רק בחלק אחד מהמערכת, איש ה‑DevOps רואה את כל התמונה — עולם שלם שמורכב ממאות רכיבים דינמיים שצריכים לעבוד בהרמוניה מושלמת.
DevOps הוא ה"מטריקס" של עולם ההנדסה המודרני — שכבה חבויה אך חיונית שמקשרת בין עולמות שונים: הפיתוח, הענן, האבטחה והתפעול. כמו ניאו, מומחי ה‑DevOps לומדים לראות את הקוד מאחורי המערכות, להבין את הדופק של השרתים, ולחולל שינוי בזמן אמת מבלי לעצור את העולם.
זהו תחום שמשלב טכנולוגיה עם פילוסופיה — שילוב של סדר וכאוס. מצד אחד, אתה מהנדס שמחפש אוטומציה מדויקת, תהליכים נקיים ו‑pipelines מושלמים. מצד שני, אתה מתמודד עם מציאות משתנה, באגים בלתי צפויים ועולמות תוכנה שמתפתחים מהר יותר מכל תקן.
הקסם האמיתי של DevOps טמון באפשרות להפוך רעיון לקוד, קוד לאפליקציה, ואפליקציה למוצר שחי, נושם ומתעדכן כל הזמן. במקום לצפות מהצד, אתה הופך למי שמאפשר את הקצב — הנווט שמכוון את המעבר המתמיד בין גרסאות, פריסות, ומשתמשים אמיתיים.
במובן מסוים, DevOps הוא לא רק מקצוע — הוא תפיסת עולם. הוא מחבר בין בני אדם ומכונות, בין יצירתיות לשיטה, ובין פיתוח מהיר לאמינות מערכתית. כמו קוסם טוב, איש DevOps יודע שהקסם הגדול באמת קורה מאחורי הקלעים – כששום דבר לא נשבר, והכול פשוט עובד.
איך עבדו לפני DevOps — ולמה זה לא עבד?
כדי להבין למה DevOps הפכה לסטנדרט בתעשייה, כדאי להבין מה היה לפניה.
בשיטת העבודה המסורתית, שנקראת Waterfall, תהליך הפיתוח היה לינארי וסגור: צוות המוצר כותב דרישות, צוות הפיתוח בונה, צוות ה-QA בודק, וצוות התפעול מעביר ופורס לייצור.
כל שלב מתחיל רק אחרי שהקודם מסתיים — ולכן מחזור שחרור שלם יכול היה לקחת חודשים.
הבעיות היו קבועות ומוכרות:
- צוות הפיתוח סיים לכתוב קוד ו"זרק" אותו לצוות התפעול — שלא היה מעורב בתהליך ולא תמיד הבין את הקוד
- באגים התגלו מאוחר, לאחר שהושקעו שבועות של עבודה
- כשמשהו נפל בייצור, האצבעות הצביעו לכל כיוון חוץ מפנימה
- שחרור גרסה חדשה היה אירוע מלחיץ שדרש הקפאת עבודה ותיאום בין מחלקות
DevOps לא המציאה כלים חדשים — היא שינתה את התרבות. במקום חומות בין מחלקות, צוות אחד עם אחריות משותפת על הקוד מרגע הכתיבה ועד לייצור. במקום שחרור אחת לחודש, pipeline אוטומטי שמאפשר לפרוס כמה פעמים ביום. במקום לגלות בעיות אצל הלקוח, ניטור רציף שמזהה תקלות לפני שמישהו מרגיש בהן.
מה אנשי Devops באו לפתור
מלחמה בין הפיתוח לתפעול היא לב הבעיה ש‑DevOps נולד לפתור: שנים של חיכוך, האשמות הדדיות וחוסר הבנה בין שני עולמות שחייבים לעבוד ביחד אבל מתנהלים כמו מחנות יריבים.
"חומת הבלבול" בין פיתוח לתפעול
בארגונים מסורתיים, הפיתוח נמדד על פי מהירות ה delivery, בעוד התפעול נמדד על יציבות ואפס תקלות – שני סטים של מדדים שסותרים זה את זה כמעט מובנה. מפתחים רוצים "לדחוף" כמה שיותר פיצ'רים, אנשי תפעול רוצים לעצור שינויים כדי לשמור על הייצור שקט.
כך נוצר מצב שבו הקוד "נזרק" מצד אחד של הארגון לצד השני, בלי באמת להבין את ההקשר: הפיתוח מסיים גרסה, אורז אותה ומעביר לתפעול, שמקבל מערכת מורכבת ברגע האחרון, בלי היכרות עמוקה, בלי תיעוד מספק ועם לחץ לעלות לאוויר מהר. הפער הזה בתפיסת העולם, בשפה ובתהליכים יוצר את מה שמכונה "חומת הבלבול" (Wall of Confusion) – נקודת השבר בין הקוד שרץ יפה על סביבת הפיתוח לבין המציאות הכאוטית של סביבת הפרודקשן.
מאחורי החומה הזו קורים כל הדברים הכואבים: "אצלנו זה עבד", "זה לא באחריות שלנו", "זה בעיה של התשתיות", "זה באג בקוד". צוותים שונים מדברים בשפות שונות, משתמשים בכלים שונים, ובמקום מערכת אחת עם זרימת ערך רציפה יש אוסף איים מנותקים שמתווכחים מי אשם כשמשהו נופל.
למה המודל הישן נכשל
במודל ה‑Waterfall הקלאסי, פיתוח תוכנה מתנהל בשלבים קשיחים: איסוף דרישות, אפיון, פיתוח, בדיקות, העברה לייצור. כל שלב מסתיים ב"זריקת אחריות" לשלב הבא, עם מעבר חד בין צוותים במקום שיתוף פעולה רציף.
הבעיה היא שהעולם המודרני זז הרבה יותר מהר מהקצב של Waterfall: דרישות משתנות, לקוחות מצפים לעדכונים תכופים, והמוצר חייב להשתפר כל הזמן. מודל שבו לוקח חודשים רק להגיע לגרסה ראשונה יוצר פער גדול מדי בין מה שהלקוח צריך עכשיו לבין מה שהמערכת יודעת לספק בפועל.
בנוסף, Waterfall מניח שאפשר "לתכנן הכול מראש", אבל במערכות מורכבות תמיד צצות בעיות רק כשהקוד פוגש את המציאות – עומסים, התנהגות בלתי צפויה בייצור, אינטגרציות שלא נבדקו בזמן אמת. כשפיתוח ותפעול מופרדים, כל בעיה כזו הופכת למריבת אחריות במקום להזדמנות ללמידה ושיפור משותף.
התוצאה היא שחרור גרסאות איטי, רמת סיכון גבוהה בכל deployment, וצוותים שחיים בפחד משינויים במקום לראות בהם חלק טבעי ובריא מהחיים של המערכת. בדיוק כאן DevOps נכנס לתמונה – לא רק כאוסף כלים, אלא כתגובה תרבותית וכירורגית לכשל המובנה של החומה בין הפיתוח לתפעול. DevOps הוא הפתרון ל"חומת הבלבול" כי הוא משנה את שיטת העבודה: במקום מחנות יריבים של פיתוח ותפעול, נוצר צוות אחד שמכוון לזרימת ערך רציפה ללקוח, עם אחריות משותפת גם על הקוד וגם על הייצור. זו לא רק קופסה של כלים, אלא תרבות, מתודולוגיה וסט עקרונות שמסנכרנים אנשים, תהליכים וטכנולוגיה סביב מטרה אחת.
תרבות (Culture)
-
תרבות DevOps שוברת את ההפרדה המלאכותית בין "הקוד שלי" לבין "המערכת שלכם" ומעודדת אחריות משותפת מקצה לקצה – מהקומיט הראשון ועד המוניטורינג בפרודקשן.
-
הדגש הוא על למידה מתמשכת, שקיפות והימנעות מתרבות האשמה: כשיש תקלה שואלים "מה נלמד מזה?" במקום "מי אשם?".
אוטומציה (Automation)
DevOps מקדם אוטומציה של כל מה שחוזר על עצמו: בנייה, בדיקות, פריסה, תצורה, provisioning של סביבות ועוד – כדי לצמצם טעויות ידניות ולהאיץ את קצב השחרור.
תהליכים כמו CI/CD מאפשרים לזרוק את הרעיון של "גרסה ענקית פעם ברבעון" ולעבור לשחרורים קטנים, תכופים ובטוחים יותר.
המשכיות (Continuous Everything)
-
ליבת הגישה היא רצף מתמשך: אינטגרציה מתמשכת (CI), בדיקות מתמשכות, פריסה מתמשכת (CD) ומשוב מתמשך מהפרודקשן.
-
במקום מחזורי פיתוח ארוכים עם הפתעות כואבות בסוף, DevOps יוצר לולאות קצרות של שינוי → בדיקה → פריסה → למידה.
מדידה (Measurement)
DevOps מבוסס על נתונים: מדידת זמני deployment, MTTR (זמן התאוששות מתקלות), אחוז כישלון של שחרורים, ביצועים ועוד – כדי לשפר באופן שיטתי.
מדידה משותפת לפיתוח ולתפעול מחברת את כולם לאותם יעדים: זמני תגובה טובים, זמינות גבוהה וחוויית משתמש יציבה.
שיתוף (Sharing)
-
DevOps מעודד שיתוף ידע, כלים ותובנות בין צוותים: שיתוף סקריפטים, תבניות CI/CD, lessons learned מאירועי תקלות (post-mortem) ועוד.
-
השיתוף יוצר שפה מקצועית משותפת בין מפתחים, אנשי תשתיות, אבטחה ו‑QA ומקטין את הפערים שהובילו לחומת הבלבול.
עקרונות נוספים חשובים
-
Shift Left: הכנסת בדיקות, אבטחה ושיקולי תפעול כמה שיותר מוקדם בתהליך הפיתוח, במקום להשאיר אותם "לסוף".
-
Everything as Code: לא רק קוד אפליקטיבי, אלא גם תשתיות, קונפיגורציות ופוליסות מנוהלים כקוד, מה שמאפשר גרסאות, ביקורת, שחזור ואוטומציה מלאה.
-
אבטחה משולבת (DevSecOps): שילוב אנשי אבטחה בתהליך DevOps כך ש‑security הוא חלק מהpipeline, ולא מחסום מאוחר שמעצור שחרורים.
אז למה צריך דבאופס?
DevOps הוא לא עוד "סט כלים", אלא שינוי עמוק בשיטת העבודה שממיס את חומת הבלבול בין הפיתוח לתפעול והופך את שני הצדדים לצוות אחד עם מטרה משותפת: לספק ערך ללקוח במהירות, ביציבות ובאיכות גבוהה. במקום משחקי "זה לא באחריות שלי", DevOps בונה תרבות שבה כולם אחראים גם על מהירות השחרור וגם על הבריאות של הפרודקשן.
בלב הגישה עומדת תרבות חדשה: מפתחים, תפעול, QA ואבטחה יושבים סביב אותו שולחן, עובדים על אותם דשבורדים, ושותפים לאותם יעדים. אין יותר "אנחנו" ו"הם", אלא צוות אחד שמסתכל על כל מחזור החיים של המערכת – מהרגע שהרעיון נולד, דרך הקוד, ועד הלוגים והמוניטורינג בזמן אמת. התרבות הזו מבוססת על שקיפות, שיתוף ידע ולמידה מתמדת מאירועים, במקום תרבות האשמה שהייתה כל כך נפוצה במודלים הישנים.
כדי לתמוך בתרבות הזו, DevOps נשען חזק על אוטומציה: הכול הופך לסקריפטים, pipelines ותהליכים אוטומטיים. בנייה, בדיקות, פריסה, הקמת סביבות – במקום טבלאות אקסל ומיילים, יש כפתור אחד או טריגר אוטומטי שכל פעם עושה את אותה פעולה, באותה צורה, בלי "שכחתי צעד". כך מצמצמים טעויות ידניות ומשחררים הרבה יותר מהר, עם הרבה פחות סיכון.
מכאן נולדת גם ההמשכיות: DevOps מחליף גרסאות ענק נדירות בזרם קבוע של שינויים קטנים, במסגרת Continuous Integration ו‑Continuous Delivery/Deployment. כל שינוי עובר מסלול קבוע: נכנס ל‑CI, נבדק אוטומטית, נמדד, נפרס לסביבות, ומשם לפרודקשן – שוב ושוב, עשרות פעמים ביום אם צריך. במקום לחיות בפחד מכל deployment, הארגון נבנה סביב יכולת לשנות מהר, ללמוד מהר ולתקן מהר.
DevOps גם מחייב מדידה רציפה של הכול: כמה זמן לוקח משינוי בקוד עד שהוא מגיע ללקוח? כמה deploymentים נכשלים? מה זמן ההתאוששות מתקלות? מה ביצועי המערכת תחת עומס? המדדים האלה הופכים לשפה המשותפת של הפיתוח והתפעול: כבר לא "השלמנו את הפיצ'ר", אלא "שיפרנו את זמן התגובה, הורדנו כמות כישלונות בפריסה, קיצרנו MTTR". דרך המדידה אפשר לזהות צווארי בקבוק, לשפר תהליכים ולהפוך את המערכת ליציבה יותר מיום ליום.
כדי שכל זה יעבוד, נדרש שיתוף עמוק: שיתוף סקריפטים, תבניות CI/CD, דשבורדים, תובנות מאירועי תקלות (post‑mortem), וידע בין צוותים. DevOps מעודד לפרק "אגרנות ידע" ולהפוך best practices לנכסים ארגוניים משותפים – מאגר של קוד, תצורות ותהליכים שכל מי שצריך יכול להשתמש בהם ולהרחיב אותם. זה השלב שבו צוותים שונים מתחילים לחשוב ולהתנהג כמו מערכת אחת ולא כמו איים מבודדים.
סביב עקרונות הליבה האלה צמחו גם הרחבות חשובות: Shift Left, שבו מכניסים בדיקות, אבטחה ותפעול כמה שיותר מוקדם בתהליך; Everything as Code, שבו לא רק האפליקציה אלא גם התשתיות, הקונפיגורציות והפוליסות מנוהלים כקוד; ו‑DevSecOps, שבו אבטחה משולבת לתוך ה‑pipeline במקום להיות מחסום עוין בשלבים המאוחרים. ביחד, כל אלה הופכים את DevOps מתגובה זמנית למשבר בין פיתוח לתפעול – לפרדיגמה מלאה שמגדירה איך ארגון טכנולוגי מודרני צריך להיראות.
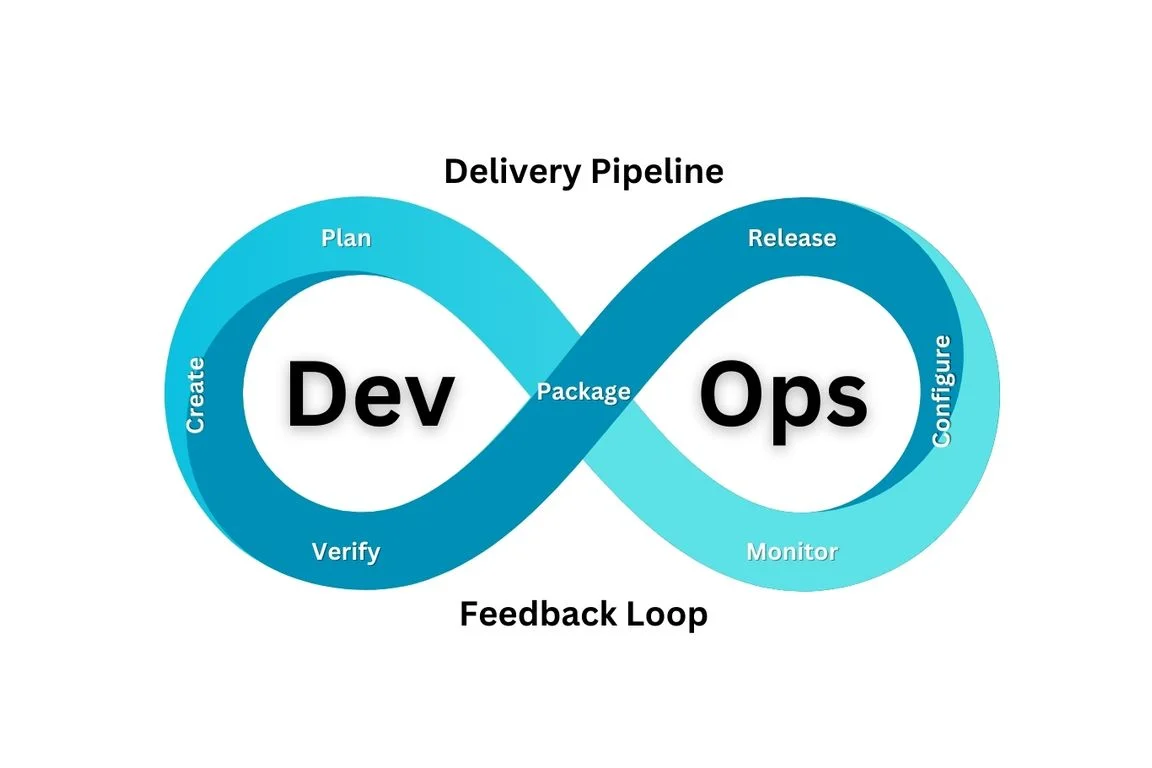
מחזור החיים של Devops
מחזור החיים של DevOps מתאר לולאה מתמשכת, שבה המערכת כל הזמן מתוכננת, מפותחת, נבדקת, נפרסת ונמדדת מחדש – בלי סוף. כל שלב בלולאה מחובר לאחרים באמצעות תהליכים אוטומטיים ושיתוף פעולה בין הצוותים.
תכנון וקידוד (Plan & Code)
בשלב התכנון והקידוד מגדירים דרישות, מפרקים אותן ל‑User Stories ומשימות, ומתכננים את הסקופ לכל איטרציה או ספרינט. כאן נבנה ה‑backlog ומשורטטת המפה למה שהצוות עומד לפתח בתקופה הקרובה.colman+1
ניהול הקוד מתבצע בעזרת בקרת תצורה (Version Control) כמו Git, שמאפשרת לעבוד בסניפים (branches), לבצע מיזוגים (merge), לעקוב אחרי כל שינוי בקובץ ולחזור אחורה אם משהו נשבר. עבודה נכונה עם pull requests, code review ו‑branches קצרי חיים היא בסיס קריטי ל‑DevOps, כי היא מאפשרת אינטגרציה תכופה ובטוחה יותר.
בנייה ובדיקות (Build & Test)
בשלב ה‑Build הקוד הופך לאובייקט ריצה: קומפילציה, אריזה ל‑Docker images, יצירת artifacts ועוד. תהליך זה צריך להיות משוחזר ואוטומטי, כך שכל build יהיה זהה ללא תלות במחשב של מפתח מסוים.
הטסטים האוטומטיים הם קו ההגנה הראשון: Unit Tests, Integration Tests ולעתים גם UI/API Tests רצים כחלק מה‑pipeline ומוודאים שכל שינוי לא שובר דברים קיימים. כאן נכנס CI (Continuous Integration) – כל קומיט שמוזג לענף המרכזי מפעיל build אוטומטי וטסטים, ומספק פידבק מהיר על איכות השינוי.
פריסה ושחרור (Release & Deploy)
בשלב השחרור והפריסה עוברים מ‑artifact מוכן לסביבת הרצה אמיתית: staging, pre‑production או production. המטרה היא שתהליך הפריסה יהיה משוחזר, צפוי וללא תלות ידנית באדם בודד.
האוטומציה כאן כוללת הגדרת שרתים ותצורה באמצעות כלים של תשתיות כקוד (Infrastructure as Code), כך שהקמת סביבות ופריסת גרסאות נעשות באופן דטרמיניסטי. CD (Continuous Delivery/Deployment) ממשיך את ה‑CI: לאחר שעברנו build וטסטים, המערכת יכולה לפרוס אוטומטית לסביבות מוגדרות, לעתים עד לרמת production, עם מנגנונים כמו blue‑green deployment או canary release כדי לצמצם סיכונים.
ניטור ותפעול (Operate & Monitor)
בשלב הניטור והתפעול בודקים איך המערכת מתנהגת בעולם האמיתי: זמני תגובה, עומסים, שיעור שגיאות, זמינות (uptime) ועוד. כלי ניטור ואיסוף לוגים מרכזים מידע משרתים, קונטיינרים ושירותים שונים, ומאפשרים לראות תמונת מצב בזמן אמת.
כדי לדעת שהמערכת "למעלה", מגדירים מדדים (SLIs), יעדים (SLOs) והתראות (alerts) – למשל עלייה בשגיאות, ירידה בביצועים או בעיות בזמינות. ברגע שיש חריגה, הצוות מקבל התראה (דרך דוא"ל, צ'אט או Pager) ויכול להגיב מהר, ובמקביל ללמוד מהאירוע ולשפר את ה‑pipeline, הקוד או התשתיות בהתאם.

הכלים הנפוצים לשימוש של אנשיי Devops
The DevOps Toolchain הוא האוסף של הכלים שמחברים בין כל שלבי מחזור החיים – מהקומיט הראשון ועד המוניטורינג בפרודקשן. לכל קטגוריה יש כלים מובילים שכדאי להכיר היטב.
ניהול קוד: GitHub, GitLab
GitHub ו‑GitLab הם פלטפורמות לניהול קוד מבוססות Git, המאפשרות אחסון ריפוזיטוריז, עבודה בענפים (branches), ביקורת קוד (Code Review) ו‑Pull/Merge Requests. סביב הקוד נוספו יכולות של ניהול Issues, ויקי ו‑DevOps מובנה, כך שהן הופכות לבסיס לכל התהליך הארגוני סביב הפיתוח.
שני הכלים תומכים באינטגרציה עמוקה עם מערכות CI/CD, סריקות אבטחה, ניהול חבילות ועוד, ולכן בפועל הם הרבה מעבר ל"שרת Git". GitHub נפוץ מאוד בקוד פתוח, בעוד GitLab פופולרי בארגונים שרוצים פתרון self‑hosted ושליטה מלאה בתשתית.
אוטומציה (CI/CD): Jenkins, CircleCI
Jenkins הוא אחד הסטנדרטים הוותיקים בעולם ה‑CI/CD, שרת אוטומציה גמיש מאוד שמאפשר לבנות pipelines מורכבים באמצעות Jenkinsfile, עם אלפי פלאגינים לכל דבר כמעט. הוא מתאים במיוחד לארגונים שרוצים שליטה מלאה בצורה שבה ה‑pipeline רץ, על גבי תשתיות שלהם.
CircleCI מספקת פלטפורמת CI/CD בענן, עם קונפיגורציה כ‑Code בקובצי YAML, דגש על מהירות בנייה, caching חכם ואינטגרציה הדוקה עם GitHub ו‑GitLab. היא מתאימה מאוד לסטארטאפים ולצוותים שמעדיפים לא לנהל שרת Jenkins בעצמם ועדיין לקבל יכולות CI/CD מתקדמות.
תשתיות (IaC): Terraform, Ansible
Terraform הוא כלי IaC דקלרטיבי, שמנהל משאבי תשתית (שרתים, רשתות, מאזני עומס, Kubernetes ועוד) בעננים כמו AWS, Azure ו‑GCP באמצעות קובצי קונפיגורציה. הוא מנהל state, תומך ב‑plan/apply, ומאפשר לבנות תשתיות מורכבות שחוזרות על עצמן בצורה אמינה.
Ansible מתמקד יותר בקונפיגורציה ו‑provisioning: התקנת חבילות, ניהול קבצי קונפיגורציה והפעלת פקודות על שרתים מרוחקים באמצעות Playbooks. שילוב של Terraform להקמת המשאבים ו‑Ansible להגדרת המערכות עצמם הפך לדפוס נפוץ בכלים של DevOps. (כאן אפשר לקשר במאמר ל"מדריך המלא ל‑IaC").
קונטיינרים: Docker, Kubernetes
Docker מאפשר לארוז אפליקציה וכל התלויות שלה לתוך קונטיינר אחיד, שמריץ את אותו build בכל סביבה – מהמחשב של המפתח ועד הפרודקשן. זה מפחית "אצלנו זה עבד" ומקל מאוד על CI/CD והעברת תוכנה בין צוותים וסביבות.mindbowser+1
Kubernetes הוא פלטפורמת orkestration לקונטיינרים, שמנהלת פריסה, סקיילינג, self‑healing ו‑service discovery עבור קלאסטרים של Docker ושירותים נוספים. הוא הפך לסטנדרט דה‑פקטו להרצת מיקרו‑שירותים בקנה מידה גדול בענן וב‑on‑prem. (כאן אפשר לקשר ל"מדריך Kubernetes למתחילים").
ענן: AWS, Azure, GCP
AWS, Microsoft Azure ו‑Google Cloud Platform הם שלושת ספקי הענן המרכזיים, המציעים שירותים מנוהלים ל‑Compute, Storage, Databases, Kubernetes מנוהל, כלי DevOps ועוד. DevOps מודרני מתבסס כמעט תמיד על אחד או יותר מעננים אלה כבסיס להרצת האפליקציה והתשתית.
כל אחד מהעננים מספק גם שירותי DevOps ייעודיים (כמו AWS CodePipeline, Azure DevOps, GCP Cloud Build), יחד עם אינטגרציות הדוקות ל‑Terraform, Jenkins, Docker ו‑Kubernetes, כך שהענן הופך לחלק אינטגרלי מה‑toolchain ולא רק "מקום עם שרתים".
מעבר לכלים: תרבות ה-DevOps
תרבות ה‑DevOps היא השכבה שמעל הכלים – בלעדיה Jenkins, Docker או Kubernetes הם רק גאדג'טים יפים שלא באמת משנים את הארגון. בתפיסה בריאה, DevOps הוא קודם כול שינוי ארגוני: איך הצוותים בנויים, איך מודדים הצלחה, איך מקבלים החלטות, ואיך מתייחסים לתקלות ולשינויים.
לא רק כלים – שינוי ארגוני
DevOps מחליף את המודל של "צוותים סילואיים" (פיתוח, תפעול, QA, אבטחה) בצוותים חוצי‑תחומים שאחראים מקצה לקצה על מוצר או שירות.
במקום למדוד פיתוח על פי "כמה פיצ'רים סיימנו" ותפעול על פי "כמה מעט תקלות היו", מודדים את כולם יחד על בסיס זמן הגעה ללקוח, יציבות, חוויית משתמש ויכולת התאוששות מהירה.
תרבות DevOps מטפחת:
שקיפות: דשבורדים משותפים, לוגים נגישים, שיתוף post‑mortems ולא "טאטוא תקלות".
למידה: אירועי כשל הם הזדמנות לשיפור תהליך, לא ציד מחשפות.
שיתוף אחריות: אותו צוות מתכנן, מפתח, משחרר ומנטר – אין "זריקת אחריות" בין מחלקות.
DevSecOps – אבטחה כחלק מהזרימה
DevSecOps הוא הרחבה טבעית של DevOps: לא "DevOps ואח"כ נביא את אבטחה לעכב", אלא שילוב אבטחה בתוך ה‑pipeline מהשלב הכי מוקדם.
במקום ביקורת חד‑פעמית לפני פרודקשן, אבטחה נכנסת דרך פעולות שיגרתיות יום יומיות כחלק מתרבות הפיתוח והשיתוף:
סריקות קוד ותלויות אוטומטיות כחלק מ‑CI.
בדיקות חדירות וסימולציות תקיפה כחלק מסבבי שחרור.
הגדרת פוליסות, סודות וגישות כקוד (Policies as Code / Secrets Management).
המפתח כאן הוא שינוי תודעתי: אנשי אבטחה הופכים לשותפים לעיצוב המערכת, לא למחסום בסוף התהליך.
MLOps – DevOps לעולם ה‑AI
MLOps מביא את אותן תפיסות DevOps לעולם של מודלים ונתונים: איך מפתחים, בודקים, משחררים ומנטרים מודלי ML בסביבה חיה.
ב‑MLOps מנהלים לא רק קוד, אלא גם: גרסאות מודלים, סטי נתונים, ניסויים, ומדדים כמו drift בנתונים או ירידה בביצועי המודל.
התרבות פה דומה:
צוותים משולבים של Data, פיתוח ותפעול במקום "המדענים בונים מודל ואחר כך זורקים אותו למפתחים".
אוטומציה של training, deployment ו‑monitoring למודלים.
אחריות משותפת על האפקט של המודל בפרודקשן – ביצועים, הטיות והשפעה עסקית.
כך, DevOps, DevSecOps ו‑MLOps יחד מתארים לא רק סט כלים, אלא דרך מודרנית לבנות ולתפעל מערכות תוכנה ו‑AI בארגון – בצורה מתמשכת, מאובטחת ואחראית.
ההצדקה והמדדים לאנשי דבאופס
DevOps משתלם כי הוא מוכיח את עצמו במספרים: ארגונים שמיישמים DevOps ברמה גבוהה משחררים מהר יותר, עם פחות תקלות ועם חיסכון ניכר בעלויות תפעול ותחזוקה.
"לפי דוח State of DevOps של DORA, צוותי עילית שעובדים עם DevOps משחררים גרסאות בתדירות גבוהה פי 208 ובמהירות פי 106 לעומת צוותים מסורתיים."
מהירות לשוק (Time to Market)
-
תהליכי CI/CD ואוטומציה מקצרים משמעותית את מחזור החיים מפיתוח לשחרור, כך שניתן להוציא עדכונים ותכונות חדשות בקצב גבוה בהרבה מהמודל הישן.
-
זמני תגובה מהירים לדרישות שוק ולפידבק משתמשים מייצרים יתרון תחרותי ישיר – מי שמוציא פיצ'רים מהר יותר, לוקח את תשומת הלב ואת הלקוחות.
יציבות ואיכות בייצור
-
DevOps משלב בדיקות אוטומטיות, ניטור רציף ושחרורים קטנים ותכופים, מה שמוביל לפחות באגים שמגיעים בכלל לפרודקשן וליכולת תיקון מהירה כשיש תקלה.
-
המיקוד במדדים כמו זמינות, MTTR (זמן התאוששות מתקלות) ושיעור כישלון של deploymentים מעלה את אמינות המערכת ומשפר את חוויית המשתמש לאורך זמן.
חיסכון בעלויות ויעילות תפעולית
-
אוטומציה של פריסה, בדיקות ותהליכי תפעול מפחיתה עבודה ידנית, מקטינה טעויות יקרות ומצמצמת את הצורך בכוח אדם לטיפול בתקלות חוזרות.
-
מערכות יציבות יותר דורשות פחות "כיבוי שריפות", מה שמפנה את הזמן של הצוותים לפיתוח ערך חדש במקום תחזוקה אינסופית.
שיתוף פעולה, שקיפות ואבטחה
-
DevOps משפר את התקשורת בין צוותים, מגדיל נראות ואחריות לאורך כל מחזור החיים, ומקטין את החיכוך בין פיתוח לתפעול.
-
שילוב DevSecOps מכניס אבטחה לתוך הזרימה, כך שהמוצר לא רק מגיע מהר ויציב – אלא גם עומד טוב יותר בדרישות רגולציה ואיומים מודרניים, מה שמפחית סיכוני סייבר יקרים.
בסך הכול, DevOps הוא מהלך עסקי: פחות זמן לשוק, פחות תקלות, פחות עלויות ויותר ערך מתמשך ללקוחות – ולכן יותר הכנסות ויתרון תחרותי לאורך זמן.
מדדי DORA מתרגמים לכסף כי הם קושרים באופן ישיר בין ביצועי הפיתוח‑תפעול לבין עלויות, הכנסות וסיכון עסקי.
תזכורת: מה הם מדדי DORA
-
תדירות פריסה (Deployment Frequency) – כמה פעמים משחררים לפרודקשן.
-
זמן מוביל לשינוי (Lead Time for Changes) – זמן מקומיט עד שעולה לפרודקשן.
-
שיעור כשל שינוי (Change Failure Rate) – אחוז הדפלוימנטים שגורמים לתקלה.
-
זמן התאוששות (MTTR / Failed Deployment Recovery Time) – כמה זמן לוקח להחזיר שירות תקין אחרי תקלה.
איך כל מדד מתורגם לחיסכון
1. Deployment Frequency – יותר שחרורים, יותר הכנסות
-
שחרורים תכופים מאפשרים להכניס פיצ'רים מהר יותר לשוק, מה שמגדיל פוטנציאל הכנסות לכל יחידת זמן (למשל שיפור המרה, ריטנשן, מכירות).
-
כל יום קיצור בזמן לשחרור של פיצ'ר בעל ערך עסקי ניתן להערכה כספית: ערך יומי משוער × מספר הימים שנחסכו = רווח/עלות הזדמנות שנחסכו.
2. Lead Time for Changes – פחות זמן "הון תקוע"
-
זמן מוביל ארוך הוא הון עצום שמושקע בפיתוח ועדיין לא מייצר ערך; קיצור lead time מפחית את זמן ההון התקוע ומשפר cash flow.
-
אפשר לתרגם זאת לכסף: עלות שעת פיתוח × (שעות/ימים שנחסכו לכל שינוי × כמות שינויים בשנה).
3. Change Failure Rate – פחות תקלות יקרות
-
כל deployment כושל גורם לעלות: שעות אדם (פיתוח, תפעול, תמיכה), פגיעה בזמינות, פיצוי לקוחות, ולעיתים נטישה.
-
הורדת CFR (נניח מ‑30% ל‑10%) מתרגמת ישירות לפחות "אירועי משבר", ופחות זמן צוותים שמבוזבז על רולבקים ותיקונים חמים.
4. MTTR – קיצור זמן השבתה
-
זמן השבתה ניתן לתמחור: הכנסות לשעה × שעות השבתה = עלות ישירה, ועוד נזק תדמיתי/חוזי.
-
הורדת MTTR מ‑4 שעות ל‑30 דקות באירועי כשל מתורגמת ל‑"חיסכון" במספר שעות השבתה בשנה × ערך שעה אבודה.
חיבור למדדים עסקיים (ROI)
-
שיפור במדדי DORA משפר גם את הסיכוי לעמוד ביעדים עסקיים; מחקרים של DORA מראים שארגונים עם ביצועים גבוהים במדדים הללו כופלים את הסיכוי לעמוד ביעדי רווח, צמיחה ושביעות רצון לקוחות.
-
בפועל, אפשר לבנות מודל ROI:
-
צד אחד – השקעה: שעות DevOps, כלים, אוטומציה.
-
צד שני – תועלת שנתית:
-
צמצום שעות השבתה × ערך שעה.
-
צמצום תקלות/דפלוימנטים כושלים × עלות ממוצעת לאירוע.
-
קיצור lead time × ערך עסקי יומי של פיצ'רים.
-
שיפור פרודוקטיביות מפתחים (פחות זמן בהמתנה/טיפול בבעיות).
-
-
כך מדדי DORA הופכים מדשבורד "יפה" למודל פיננסי: כל שיפור במספרים ניתן להמרה לחיסכון/תוספת הכנסה מדודים, ולהראות בצורה ברורה למה השקעה ב‑DevOps משתלמת עסקית.
השפעת MTTR (זמן התאוששות מתקלות) על עלויות התפעול היא ישירה ומשמעותית, כי כל דקה נוספת של השבתה מתורגמת להפסדים כספיים מוחשיים.
נוסחה בסיסית לחישוב השפעה
עלות השבתה שעתית = (הכנסות יומיות ÷ 24) + עלות צוותי תמיכה + נזק תדמיתי/קנסות
חיסכון שנתי = (שעות השבתה שנחסכו) × עלות שעתית × מספר אירועים בשנה
דוגמה 1: חברת מסחר אלקטרוני
-
נחות: MTTR = 4 שעות לאירוע, 10 תקלות בשנה.
השבתה כוללת: 4 × $10,000/שעה (אובדן מכירות) = $40,000 לאירוע.
סה"כ שנתי: $400,000 + שעות צוות ($200/שעה × 40 שעות = $8,000).
עלות כוללת: ~$408,000. -
טוב: MTTR = 30 דקות (0.5 שעות), אותם 10 אירועים.
השבתה: 0.5 × $10,000 = $5,000 לאירוע.
סה"כ שנתי: $50,000 + שעות צוות ($200 × 5 שעות = $1,000).
חיסכון: $357,000 בשנה (87% שיפור!).
דוגמה 2: חברת שירותים פיננסיים
-
עלות השבתה: $500,000 לשעה (עסקאות, קנסות, אובדן אמון).
-
לפני: MTTR = 3 שעות, 12 אירועים בשנה → 36 שעות השבתה = $18 מיליון.
-
אחרי: MTTR = 45 דקות (0.75 שעות) → 9 שעות השבתה = $4.5 מיליון.
-
חיסכון: $13.5 מיליון בשנה (75% הפחתה).
דוגמה 3: סקר New Relic (ממוצע גלובלי)
-
עלות תקלה שנתית ממוצעת: $7.75 מיליון לארגון.
-
ארגונים עם observability מלאה (שמקצר MTTR ב‑25%+) חווים עלות תקלות ב‑37% פחות:
חיסכון: ~$2.87 מיליון לארגון בשנה.
השפעות נוספות מעבר להכנסות
| היבט | השפעה של MTTR נמוך | חיסכון משוער |
|---|---|---|
| פרודוקטיביות צוות | פחות "כיבוי שריפות", יותר זמן לפיתוח | $100K–$500K/שנה (שעות צוות × עלות שעה) |
| שביעות רצון לקוחות | פחות השבתות = פחות נטישה | 5–10% שיפור ריטנשן × LTV לקוח |
| נזק תדמיתי | פחות חדשות שליליות, יותר המלצות | $50K–$1M לאירוע גדול |
יום בחיי איש דבאופס
תפקיד ה-DevOps Engineer הוא אחד התפקידים המבוקשים, הדינמיים ולעיתים גם המלחיצים ביותר בהייטק. זהו התפקיד שמחבר בין המפתחים (Dev) לבין התפעול והשרתים (Ops), כשהמטרה העליונה היא לגרום לקוד להגיע לסביבת הייצור (Production) בצורה מהירה, בטוחה ואוטומטית.
יום בחיי איש DevOps משתנה מאוד בהתאם לגודל החברה ולתרבות הארגונית, אבל הנה הצצה טיפוסית ללו"ז כזה, המשלב בין תכנון אסטרטגי לבין "כיבוי שריפות":
בוקר: קפה, לוגים וסטטוס מערכת
הבוקר של איש ה-DevOps מתחיל בדרך כלל בבדיקת הדופק של המערכת. לפני שמתחילים לכתוב קוד, צריך לוודא שהלילה עבר בשקט.
09:00 – בדיקת Dashboards: מבט מהיר על מסכי הניטור (כמו Grafana או Datadog). האם השרתים עמוסים? האם היו נפילות בלילה? האם הגיבויים הצליחו?
09:30 – Daily Standup: ישיבת צוות קצרה. כאן מסנכרנים משימות:
"אני משדרג היום את הקלאסטר של ה-Kubernetes."
"אני עוזר לצוות ה-Backend עם בעיית הרשאות ב-AWS."
10:00 – מעבר על התראות (Alerts): סינון רעשים. אם היו התראות "שווא" בלילה, זה הזמן לכוונן את המערכת כדי למנוע אותן בעתיד (Alert Fatigue הוא אויב ידוע).
צהריים: עבודה "עמוקה" (Deep Work)
זה הזמן שבו מנסים לקדם פרויקטים של תשתית ולשפר תהליכים. המטרה: אוטומציה. אם אתה עושה משהו פעמיים ידנית – בפעם השלישית תכתוב לו סקריפט.
כתיבת קוד (Infrastructure as Code): עבודה עם Terraform או Pulumi כדי להרים שרתים, מסדי נתונים ורשתות בענן (AWS/Azure/GCP) באמצעות קוד בלבד.
שיפור ה-CI/CD Pipelines: העבודה הקלאסית. מפתח מתלונן שה"בילד" (Build) לוקח 20 דקות? איש ה-DevOps יצלול לתוך הקונפיגורציה של Jenkins או GitHub Actions כדי לקצר את זה ל-5 דקות.
ניהול קונטיינרים: כתיבת Helm Charts או Dockerfiles כדי לוודא שהאפליקציה רצה בצורה זהה גם במחשב של המפתח וגם בשרת האמיתי.
נקודה חשובה: איש DevOps טוב הוא לא זה שמתקן שרתים ידנית, אלא זה שבונה מערכת שמתקנת את עצמה (Self-healing).
🔥 אחר הצהריים: "כיבוי שריפות" ושיתוף פעולה
למרות התכנונים, הבלת"מים (בלתי מתוכנן) הם חלק בלתי נפרד מהיום.
14:00 – "זה עובד אצלי במחשב": מפתח פונה אליך כי הקוד שלו נכשל בטסטים או לא מצליח להתחבר ל-Database בסביבת הטסטים. אתה נכנס לכובע של "חוקר" – בודק לוגים, הרשאות רשת וגרסאות ספריות.
15:00 – אירוע Production (חס וחלילה): האתר איטי פתאום? לקוחות מתלוננים על שגיאות 500?
כולם עוצרים הכל.
פותחים "חדר מלחמה" (War Room).
מבצעים Rollback (חזרה לגרסה קודמת) במידת הצורך.
אחרי שהאש כבתה, כותבים Post Mortem – מסמך שמנתח מה קרה ואיך מונעים את זה להבא.
סוף היום: לימוד ומחקר
הטכנולוגיה בתחום ה-DevOps טסה קדימה בקצב מסחרר. מה שהיה סטנדרט לפני שנתיים, היום נחשב מיושן.
קריאה על כלים חדשים (למשל: מעבר ל-ArgoCD, כלי AI לניהול ענן).
בדיקת עלויות ענן (FinOps) – איך חוסכים לחברה כסף על שרתים מיותרים שנשארו דולקים.
ההבדל בין עבודה מתוכננת לבלת"מים
טבלה זו ממחישה את הדילמה התמידית של התפקיד:
| סוג עבודה | דוגמאות | התחושה |
| מתוכננת (Proactive) | שדרוג תשתיות, כתיבת אוטומציה, שיפור אבטחה. | סיפוק, בנייה, רוגע. |
| תגובתית (Reactive) | טיפול בנפילות שרתים, באגים דחופים ב-Pipeline, תמיכה במפתחים תקועים. | לחץ, אדרנלין, קטיעת רצף המחשבה. |
סיכום: למה אנשים בוחרים בזה?
למרות הלחץ והאחריות הגדולה (ה"מפתחות" לשרתים בידיים שלך), זהו תפקיד מתגמל מאוד:
ראייה רוחבית: אתה מבין איך כל המערכת עובדת, מקצה לקצה.
כוח העל של האוטומציה: יש סיפוק אדיר בללחוץ על כפתור ולראות תשתית שלמה קמה מאפס תוך דקות.
ביקוש ושכר: זהו אחד התפקידים המתוגמלים ביותר בתעשייה.
טבלת שכר דבאופס
הנה טבלת שכר מעודכנת לשנת 2025 ותחזית לשנת 2026 עבור אנשי DevOps בישראל. הנתונים מבוססים על איסוף מסקרי שכר של חברות השמה מובילות (כמו Gotfriends, TechJob, Nisha) ומגמות שוק נוכחיות.
חשוב לזכור: תחום ה-DevOps הוא אחד המתוגמלים ביותר בהייטק, ולרוב נמצא בטופ של טבלאות השכר לצד מפתחי אלגוריתמים וארכיטקטים, בשל המחסור הכרוני באנשי תשתיות איכותיים.
טבלת שכר DevOps – שנת 2025 (אלפי ש"ח ברוטו לחודש)
הטבלה מציגה טווחים, כאשר הרף התחתון מייצג חברות קטנות/מסורתיות והרף העליון מייצג חברות הייטק גדולות (Corporates) וסטארטאפים מבוססים (Unicorns).
| רמת ניסיון | הגדרה / שנות ניסיון | טווח שכר ממוצע (₪) | הערות ומגמות |
| Junior | 0-2 שנים | 18,000 – 26,000 | שכר הכניסה עלה. לרוב נדרש רקע קודם (כמו SysAdmin) כדי להיכנס. |
| Mid-Level | 3-5 שנים | 28,000 – 38,000 | הקפיצה הגדולה ביותר בשכר. כאן נמדדת היכולת לעבוד עצמאית. |
| Senior | 5-9 שנים | 38,000 – 50,000 | הביקוש לדרג הזה הוא הגבוה ביותר. שכר בחברות טופ יכול לחצות את ה-50k. |
| Team Lead | ראש צוות | 42,000 – 58,000 | תלוי מאוד בגודל הצוות ובאחריות (Hands-on vs Management). |
| Expert / Consultant | פרילאנס/מומחה | 600 – 900 ש"ח (שעתי) | יועצים לרוב מתמחים בנישות ספציפיות (כמו K8s Security, FinOps). |
תחזית לשנת 2026: לאן השוק הולך?
לפי התחזיות הכלכליות והטכנולוגיות הנוכחיות (כולל נתונים מחברות השמה שצופות ל-2026), אנו צפויים לראות את המגמות הבאות:
1. עלייה מתונה אך יציבה (כ-5% עד 8%):
השכר ב-2026 צפוי להמשיך לטפס, אך לא בקפיצות המטורפות של 2021-2022. הדגש יעבור מ"גיוס בכל מחיר" ל"גיוס טאלנטים ספציפיים".
צפי ג'וניורים: 20k - 27k (עלייה קלה ברף הכניסה).
צפי סניורים: 40k - 53k (התקרה ממשיכה להימתח עבור מומחים).
2. הופעת תפקיד ה-AI-Ops:
ב-2026, אנשי DevOps שידעו להטמיע ולתחזק תשתיות של בינה מלאכותית (LLMs, GPU Clusters) ייהנו מפרמיית שכר של 15%-20% מעל הממוצע בטבלה.
3. פערים גדלים בין "מפעילים" ל"מהנדסים":
השוק יתגמל הרבה פחות אנשי DevOps שיודעים רק "ללחוץ על כפתורים" ב-Jenkins, והרבה יותר כאלו שיודעים לכתוב קוד מורכב (Python/Go) ולבנות פלטפורמות פנימיות (Platform Engineering).
4. דגש על FinOps (חיסכון בעלויות ענן):
בגלל המצב הכלכלי, חברות מחפשות בנרות אנשי DevOps שיודעים לא רק להרים שרתים, אלא לייעל אותם. מומחיות ב-FinOps תהפוך לקלף מיקוח חזק בשכר.
💡 מה הכי משפיע על המיקום שלך בטבלה?
Linux Deep Dive: הבנה עמוקה של מערכת ההפעלה (Kernel, Networking) שווה יותר מהיכרות שטחית עם הרבה כלים.
Cloud Agnostic: ידע ב-AWS הוא סטנדרט. ידע גם ב-GCP או Azure הוא יתרון משמעותי.
Kubernetes: שליטה ב-K8s היא כבר לא "בונוס", אלא דרישת סף למשכורות הגבוהות (מעל 30k).
איך ללמוד להיות איש Devops
"ראינו איך נראה יום של איש DevOps: בין אוטומציה מתוחכמת לפתרון בעיות קריטיות בזמן אמת. הבנו שהשכר ב-2026 הולך לתגמל רק את אלו שיודעים לבנות תשתיות, לא רק לתפעל אותן.
בקורס ה-DevOps שלנו, אנחנו לא מלמדים אתכם רק 'כלים', אנחנו מלמדים אתכם מקצוע.
במהלך המסלול תעברו את כל התחנות הקריטיות שהזכרנו:
הקמת תשתיות בקוד (IaC): תלמדו לשלוט ב-Terraform כדי להרים קלאסטרים בלחיצת כפתור.
הלב של התעשייה: התמחות עמוקה ב-Docker ו-Kubernetes (הנכס הכי חזק שלכם בראיונות עבודה).
ניטור ואבטחה: איך בונים מערכת שמתריעה על תקלות לפני שהלקוח מרגיש אותן.
פרויקט ה-Hands-on הגדול: סימולציית 'שבוע ב-Production' שתכין אתכם ליום הראשון בעבודה החדשה.
השוק מחכה לאנשי DevOps איכותיים. המקום שלכם מחכה לכם כאן."
צרו קשר עם יועץ הלימודים והקריירה שלנו ליותר מידע.
שאלות נפוצות FAQ
- האם צריך לדעת לתכנת כדי להיות DevOps?
- כן, אבל לא ברמה של מפתח אפליקציות מורכבות. DevOps דורש כתיבת סקריפטים ואוטומציה בשפות כמו Bash, Python או Go – בעיקר לניהול תהליכים, parsing לוגים, אינטגרציות בין כלים וטיפול בנתונים.הידע החשוב יותר הוא לוגיקה תכנותית, הבנת JSON/YAML, עבודה עם APIs ויכולת לבנות pipelines מורכבים. רוב העבודה היא קונפיגורציות ותשתיות כקוד, לא פיתוח מוצרים. אם יש רקע בסיסי בתכנות (למשל Python), למידה של 2-3 חודשים תספיק לרמה מקצועית ראשונית.
- מה ההבדל בין SysAdmin ל-DevOps?
- SysAdmin מסורתי מתמקד בתפעול יומיומי: ניהול שרתים, גיבויים, פאצ'ינג, פתרון תקלות "כיבוי שריפות" ותחזוקה ידנית.
- DevOps בונה מערכות שעובדות מעצמן: אוטומציה מלאה של פריסה, בנייה, תצורה וניטור, כך שהתפעול הופך לניטור מדדים + תיקון שורשי הבעיה במקום טיפול סימפטומטי.
-
SysAdmin DevOps עבודה ידנית חוזרת הכול כקוד + אוטומציה מגיב לתקלות מונע תקלות מראש אחראי על יציבות אחראי על מהירות + יציבות "שרתים שלי" תשתית משותפת עם Dev - DevOps הוא SysAdmin שהפך למהנדס תהליכים.
- כמה זמן לוקח ללמוד DevOps?
- תלוי ברקע:
למתכנתים: 3-6 חודשים לרמה ג'וניור (CI/CD, Docker, ענן בסיסי).
ל‑SysAdmin: 2-4 חודשים (סקריפטינג + כלי DevOps).
מאפס: 8-12 חודשים לרמה עבודה.
- תלוי ברקע:
מסלול מומלץ למי שרוצה להכנס להיות איש Devops:
-
חודש 1: Linux, Git, Bash/Python, Docker.
-
חודש 2: CI/CD (Jenkins/GitLabCI), Terraform, ענן (AWS/GCP).
-
חודש 3: Kubernetes, monitoring (Prometheus/Grafana), פרויקט אמיתי.
- טיפ: בנו תיק עבודות עם pipeline אמיתי שמפרס אפליקציה מ-Git לפרודקשן – זה מה שמעסיקים מחפשים.
RT-ED מציעה מסלול מזורז עם פרויקטים כאלה שמכין ישירות לראיונות.
- מה זה DevOps בפשטות? DevOps היא שיטת עבודה שמחברת בין צוות הפיתוח (Dev) לצוות התפעול (Ops) בחברות הייטק. במקום שכל צוות יעבוד בנפרד ו"יזרוק" קוד מעבר לגדר, DevOps יוצרת תהליך משותף ואוטומטי שמאפשר לשחרר גרסאות תוכנה מהר יותר, בצורה יציבה ועם פחות תקלות.
- מה ההבדל בין DevOps ל-Agile? Agile היא מתודולוגיה לניהול פרויקטים שמתמקדת בעבודה במחזורים קצרים (ספרינטים). DevOps היא הרחבה של הרעיון הזה — היא לוקחת את הגמישות של Agile ומוסיפה עליה אוטומציה, שיתוף פעולה עם תפעול, וניטור בסביבת הייצור. בפועל רוב הצוותים משתמשים בשניהם יחד.
- מה עושה איש DevOps ביום יום? איש DevOps אחראי על בניית ותחזוקת ה-pipeline — כלומר התהליך האוטומטי שלוקח קוד של מפתח ומעביר אותו דרך בדיקות, build ועד לפריסה בסביבת הייצור. בנוסף הוא מנהל תשתיות ענן, מגדיר כלי ניטור, ומוודא שהמערכות יציבות ומוכנות לכל עומס.
- אילו כלים צריך לדעת כדי להיות DevOps?
- הכלים המרכזיים שמעסיקים מחפשים: Linux ו-Bash לניהול מערכות, Git לניהול קוד, Docker ו-Kubernetes לקונטיינרים, Jenkins או GitHub Actions לCI/CD, Terraform ו-Ansible לתשתיות כקוד, ו-AWS כפלטפורמת ענן. בנוסף כדאי לדעת Python לאוטומציה ו-Prometheus/Grafana לניטור.
- כמה מרוויח איש DevOps בישראל?
- שכר מתחיל לאיש DevOps Junior עומד על כ-18,000–23,000 ₪ לחודש. ברמת Senior מדובר על 26,000–32,000 ₪, וברמת Team Lead ניתן להגיע ל-36,000 ₪ ומעלה. אלו מהשכרות הגבוהות ביותר בתעשיית ההייטק הישראלית.
- האם צריך ניסיון בתכנות כדי ללמוד DevOps?
- לא חייבים להיות מפתחים, אבל רקע טכני עוזר מאוד. אנשים שמגיעים מ-IT, ניהול רשתות, QA או sysadmin מתאימים מאוד לתחום. מי שמגיע ללא ניסיון כלל יצטרך לעבור קורס מקיף שמלמד גם את הבסיס — Linux, Python ורשתות — לפני הכלים הייעודיים.
- מה זה CI/CD ולמה זה חשוב ב-DevOps? CI/CD
- הם שני עקרונות מרכזיים ב-DevOps. Continuous Integration (אינטגרציה רציפה) אומר שכל שינוי קוד עובר בדיקות אוטומטיות מיד עם ה-commit. Continuous Deployment (פריסה רציפה) אומר שקוד שעבר את הבדיקות עולה אוטומטית לסביבת הייצור. ביחד הם מאפשרים לשחרר גרסאות חדשות כמה פעמים ביום במקום פעם בחודש.
- מה זה DevSecOps?
- DevSecOps היא הרחבה של DevOps שמשלבת אבטחת מידע (Security) כחלק אינטגרלי מה-pipeline, ולא כשלב נפרד בסוף התהליך. במקום לבדוק אבטחה רק לפני שחרור, ב-DevSecOps כל commit עובר סריקות אבטחה אוטומטיות. הגישה הזו הופכת נפוצה יותר ויותר בחברות שעובדות עם מידע רגיש.


- הסבר קצר מה זה Devops
- מה אנשי Devops באו לפתור
- תרבות (Culture)
- אוטומציה (Automation)
- המשכיות (Continuous Everything)
- מדידה (Measurement)
- שיתוף (Sharing)
- עקרונות נוספים חשובים
- אז למה צריך דבאופס?
- מחזור החיים של Devops
- הכלים הנפוצים לשימוש של אנשיי Devops
- מעבר לכלים: תרבות ה-DevOps
- ההצדקה והמדדים לאנשי דבאופס
- יום בחיי איש דבאופס
- טבלת שכר דבאופס
- איך ללמוד להיות איש Devops
- שאלות נפוצות FAQ